There are substantial instructional videos on the Internet, which provide us tutorials for completing
various tasks. Existing instructional video datasetsonly focus on specifc steps at the video level,
lacking experiential guidelines at the task level. whichcan lead to beginners struggling to learn new
tasksdue to the lack of relevant experience. Moreover the specific steps without guidelines are trivial
and unsystematic, making it diffcult to provide a clear tutorial.
To address these problems, we present the GUIDE (Guideline-Guided) dataset, which
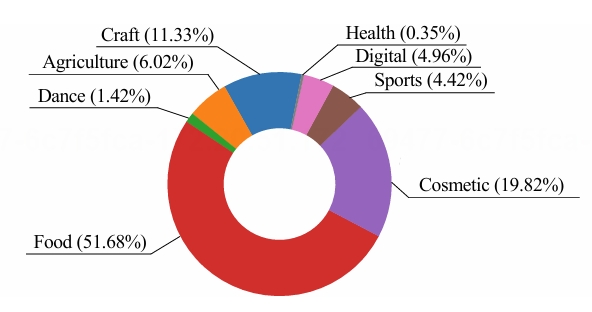
contains 3.1K videos of 600 instructional tasks in 8 domains related to our daily life. Specifcally, we
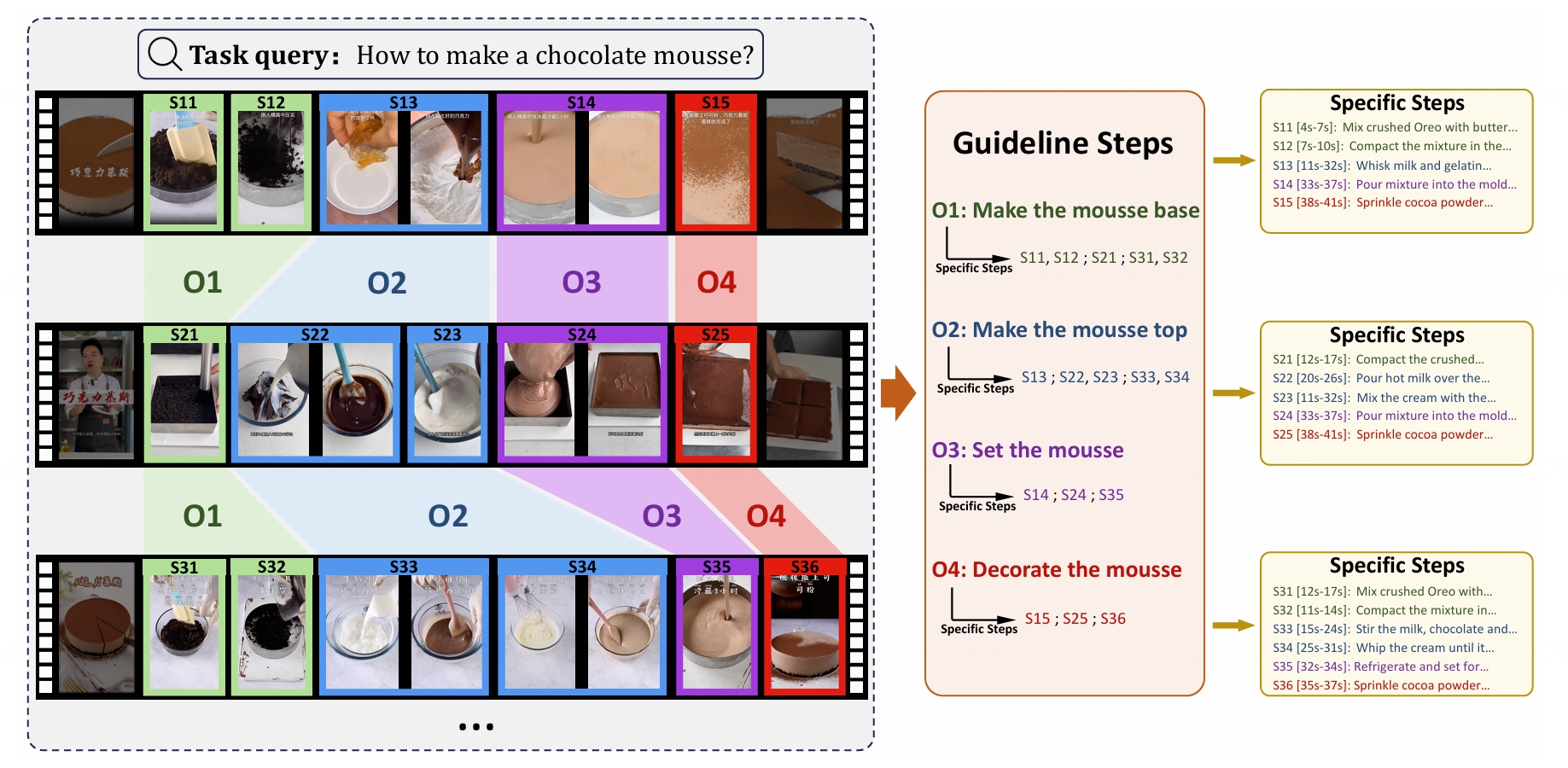
annotate each instructional task with a guideline, representinga common pattern shared by all task-related
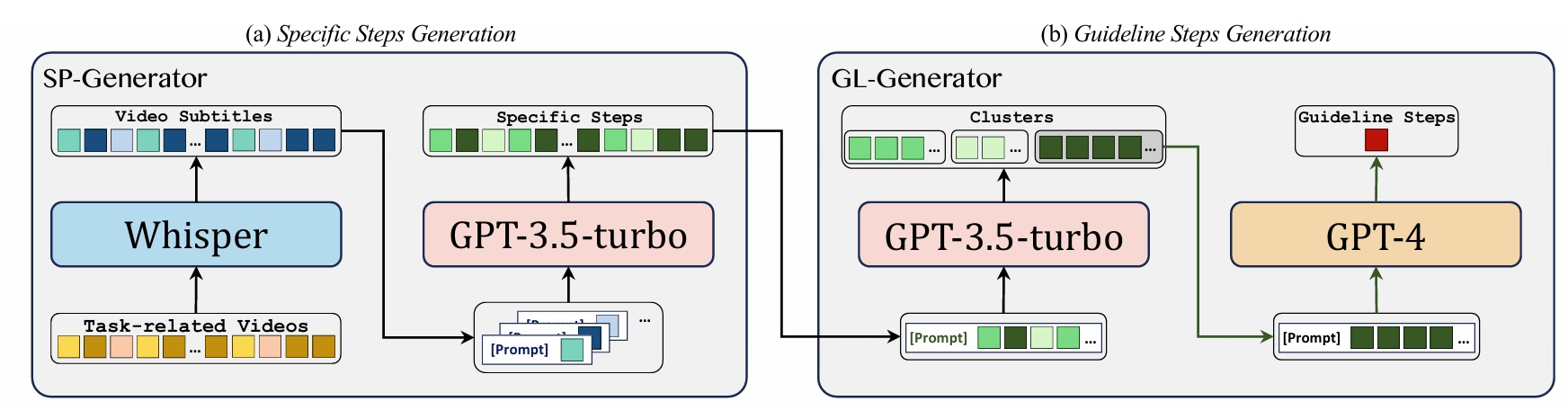
videos. On this basis, we annotate systematic specifc steps including their associated guideline steps,
specifcstep descriptions and timestamps.
Our proposed benchmark consists of three sub-tasks to evaluatecomprehension ability of models:(1)
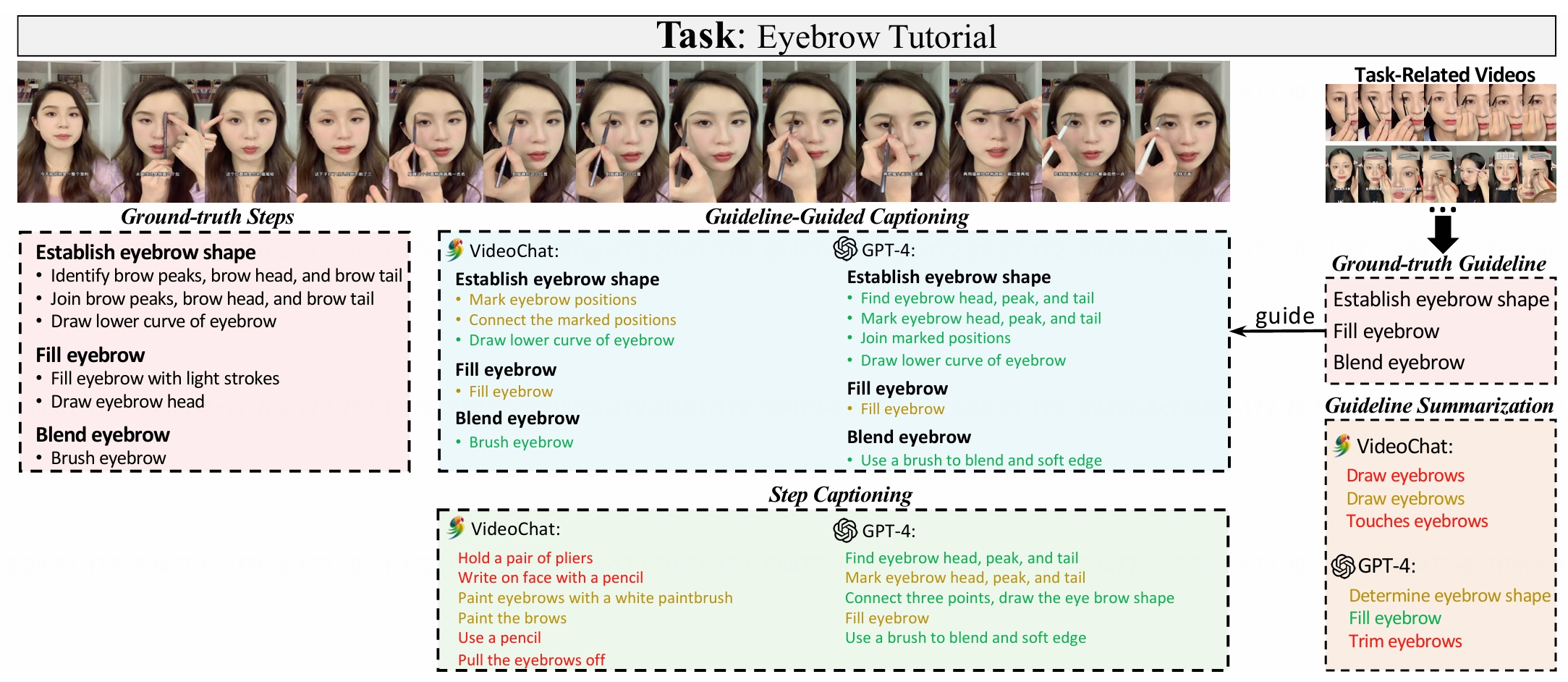
Step Captioning: models have to generate captions for specifcsteps from
videos.(2)Guideline Summarization: models have to mine the common pattern in task related
videos and summarize a guideline from them.(3)Guideline-Guided Captioning: models have to
generate captions for specifc steps under the guideof guideline. We evaluate plenty of foundation models
with GUIDE and perform in-depth analysis. Given the diversity and practicality of GUIDEwe believe that it
can be used as a better benchmark for instructional video comprehension.